recomendation systems
9 Jan 2018
This post is to resume different options to do make a recomendation system
All recommendations have two components (ther characteristicas could be known or unknown):
- items to be recommended, the content (m)
- users to recommend items (n)
Content Based recommendation I
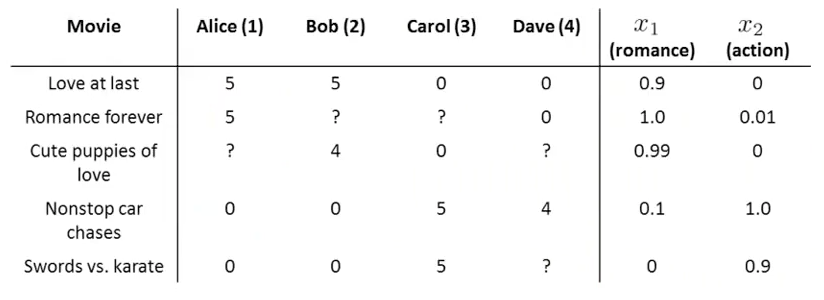
This example is extracted from coursera machine learning course, that basically consists on make a linear regression with the content features and the existing ratings of each user.
It’s important to have some ratings from user on other contents in order to guess his preference from the new content.
$x^{(i)}$ = feature vector for each content ($k$ features).
$\theta^{(j)}$ = parameter vector for user j, $\theta^{(j)} \in \mathbb{R}^{k+1}$ because the bias component
$y^{(i,j)}$ = rating by user j on content i (if defined) $r(i,j) = 1$ if user $j$ has rated the content $i$ (O otherwise)
You have all $x^{(i)}$ bu some $y^{(i,j)}$ are not defined.
Solution: make a linear regresion with known parameters and use the result to compute the gaps: $y^{(i,j)}$
Learn $\theta^{(j)}$ (parameter for user j):
Gradient descent update.
Repeat:
For each user $j$, content $i$, compute rating as $(\theta^{(j)})^T(x^{(i)})$
Colaborative Filtering I
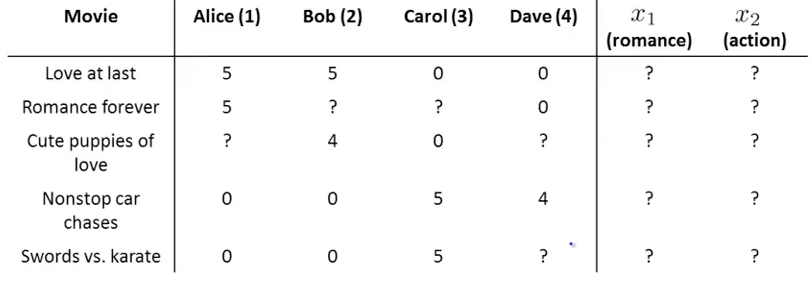
How to retrieve content features from user ratings? The same algorithm but derivative is from $x^{(i)}$:
Learn $x^{(i)}$ (content i):
Gradient descent update.
Repeat:
Colaborative Filtering II
This is the complete colaborative algorithm. Both content features and ratings are calculated from user current ratings $y^{(i,j)}$.
Minimizing $x^{(1)},….x^{(n_m)} \text{ and }\theta^{(1)},….\theta^{(n_u)}$
Gradient descent update.
Initialize randomly $x^{(i)}_k$ and $\theta^{(j)}_k$ and repeat: