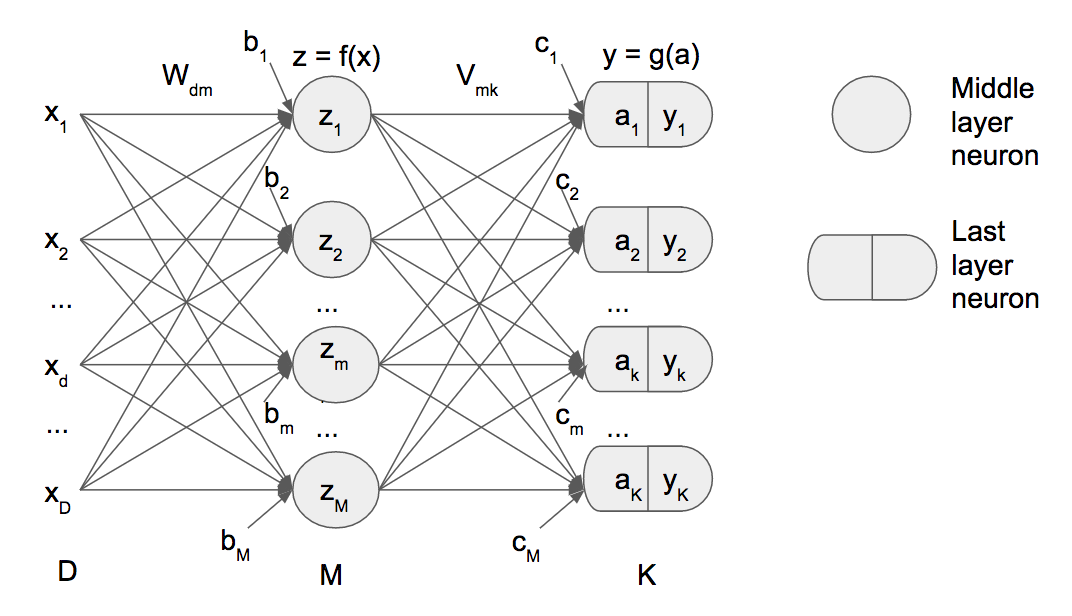
Neural network L1 and L2 regulatization
30 Dec 2017
Demonstration of L1 and L2 regularization in back recursive propagation on neural networks
Purpose of this post is to show that additional calculations in case of regularization L1 or L2.
Regularization ins a technique to prevent neural networks (and logistics also) to over-fit. Over-fitting occurs when you train a neural network that predicts fully your trained data but predicts poorly on any new test data.
Regularization increases error (or reduces likelihood).
The two most common forms of regularization are called L1 and L2. In L2 regularization (the most common of the two forms), you modify the error function you use during training to include an additional term that adds a fraction (usually given Greek letter lower case lambda) of the sum of the squared values of the weights. So larger weight values lead to larger error, and therefore the training algorithm favors and generates small weight values.
L1 regression consists of search min of cross entropy error:
as well as satisfy the constraint that
From lagrange multiplier we can write the above equation as,
$s$ is a constant so we can write the above equation as:
L2 regularization is also known as Ridge Regression.
L1 regularization is also known as LASSO.
The turning parameter $\lambda$ in both cases controls the weight of the penalty. Increase $\lambda$ in LASSO causes least significance coefs to be shrunken to 0, and is a way to select the best features.
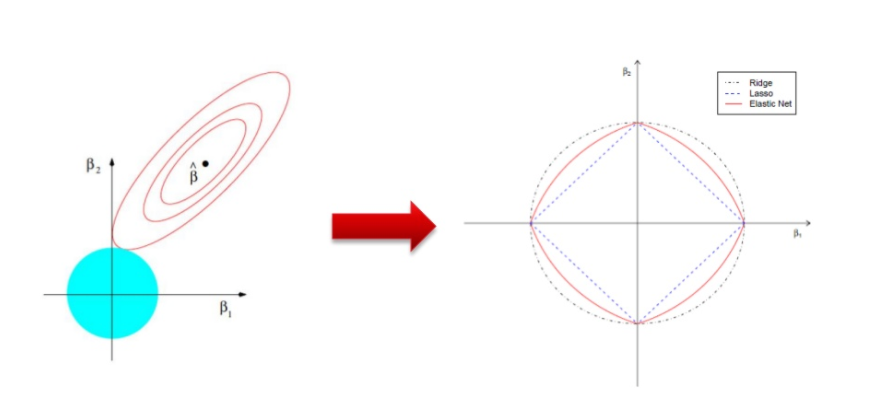
source: Data Science - Part XII - Ridge Regression, LASSO, and Elastic Nets
If $f(\beta)$ is the objective function like the cross entropy error, The minimum is in the middle of the circles, that is the non penalized solucion.
If we add a different objective $g(\beta)$ with colour blue in the graph, we get that larger $\lambda$ gets a “narrow” contour plot.
Now we have to find the minimum of the sum of this two objectives: $f(\beta)+g(\beta)$. And this is achieved when two contour plots meet each other.
LASSO will probably meet in a corner that makes some $\beta$ to be 0 and this is useful to feature selection. This does not happen in the Ridge regression.
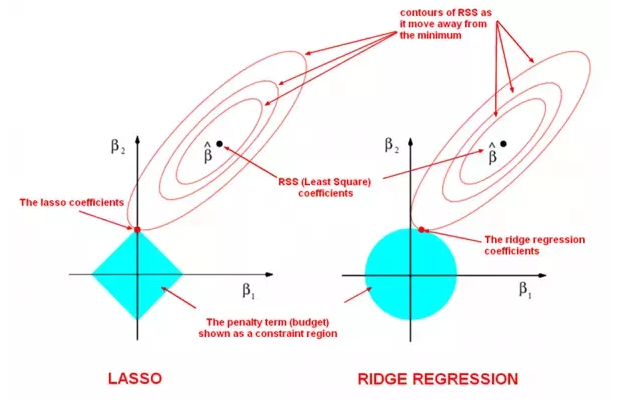
source: source of graph
A general form for penalty term can be writen as: