Gradiend descent
26 Dec 2017
Demonstration of normal (Batch) gradient descend formulas
$y$ is the training input (always 0 or 1)
$m$ is the size of de dataset input x
$w$ are the parameters of logistic regression
First assumption is that can aproximate the likehood with the sigmoid function:
Cost funcion (is the likelihood negated) is the error on every iteration (cross entropy error) and depends on likelihood.
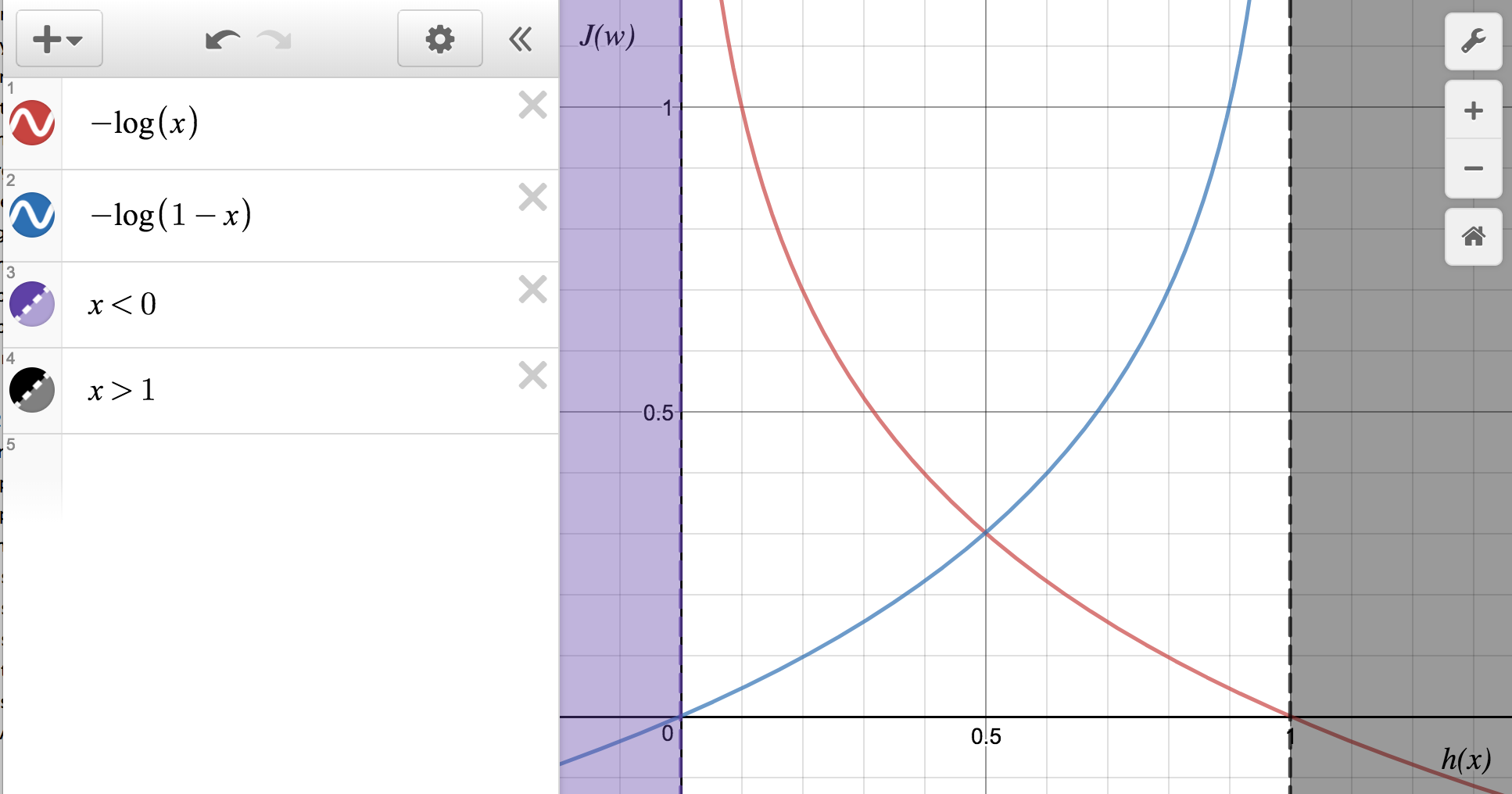
This formula is derived from calculation of likelihood of the $m$ inputs as:
Note: we assume that the output has an output binary class k = 2, that have redundant and opposed probabilities.
Retuning to the cost ($J(w)$):
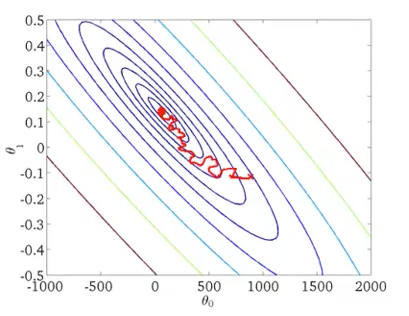
There is a global minimum thar can be achieved using gradient descent.
There are several types of gradient descent implementation:
- Batch gradient descent: iteration (new coefs) is done as the sum of all training examples
- Stochastic gradient descent: iteration on each example, converges faster than batch gradient descent in case of large training dataset.
- Mini-batch gradient descent: iteration on a group of $b$ examples, in some cases can converge faster than batch or stochastic.
- Stochastic gradient descent with momentum: each gradient has a momentum added from the previous gradient:
Important implementation concepts:
- Debug results to adjust the learning rate
- Possibly set dinamic learning rate as: $\alpha = \dfrac{const_1}{interationNumber + const_2}$ so learning rate decreases as it aproaches to the minimum.
An special case of stochastic gracient descent is the Online learning. Learning is done continuously from a source flow that generates training examples. Each example is used for train and ignored (not stored).
source: coursera machine learning course
Glosary
- MLE: Maximum Likelihood Estimation
- sigmoid: function to map $[-\infty,\infty]$ to $[0,1]$
- Epoch: Epoch means one iteration of Stochastic Gradient Descent