Neural network forward propagation
16 Dec 2017
Demonstration of forward propagation on neural networks
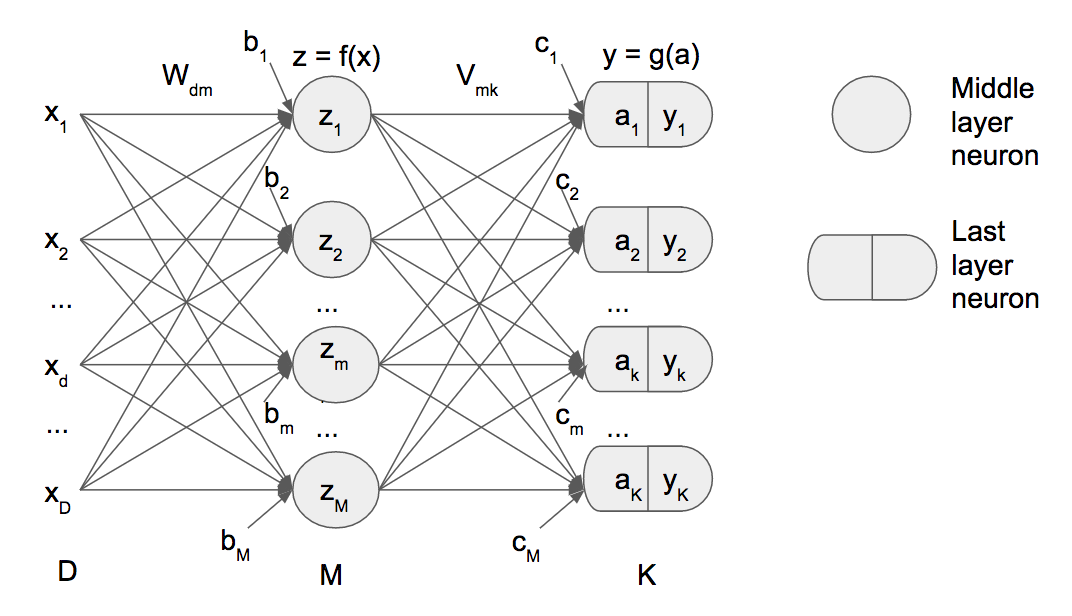
$x$ input for first hidden layer
$D$ number of features from x
$z$ input for hidden layer
$M$ number of hidden layer of network
$K$ Number of output classification classes
$a$ input of last layer
$y$ output of last layer
$t$ trained classification output [0,1]
$W_{dm}$ Matrix of weights from input to hidden layer $z$
$b$ Bias of input hidden layer $z$
$V_{mk}$ Matrix of weights from hidden layer to output $y$
$c$ Bias of input hidden layer $z$
$f(x)$ is the function of the middle neuron [$sigmoid(x)$, $tanh(x)$, $reLU(x)$]
$g(x)$ is the function of the last neuron [$sigmoid(x)$, $softmax(x)$, $linear(x)$]
Example for $f(x)$ in tanh:
Last layer example for $g(x)$ in softmax:
Softmax is a vector function, every output depends on all inputs ($a_k$):
Neural network foward propagation formulas in matrix form:
- From one layer to the next layer
- From the last but one hidden to the output (sigmoid):
- From the last but one hidden to the output K>2 (softmax):